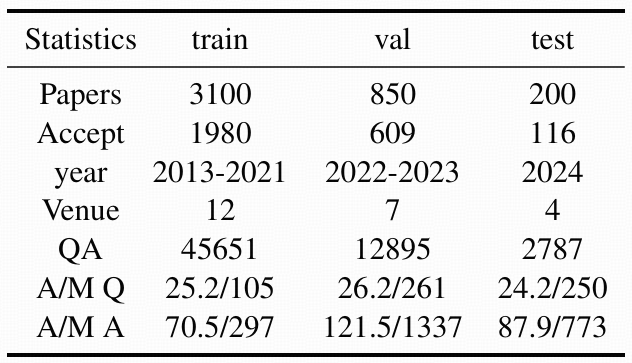
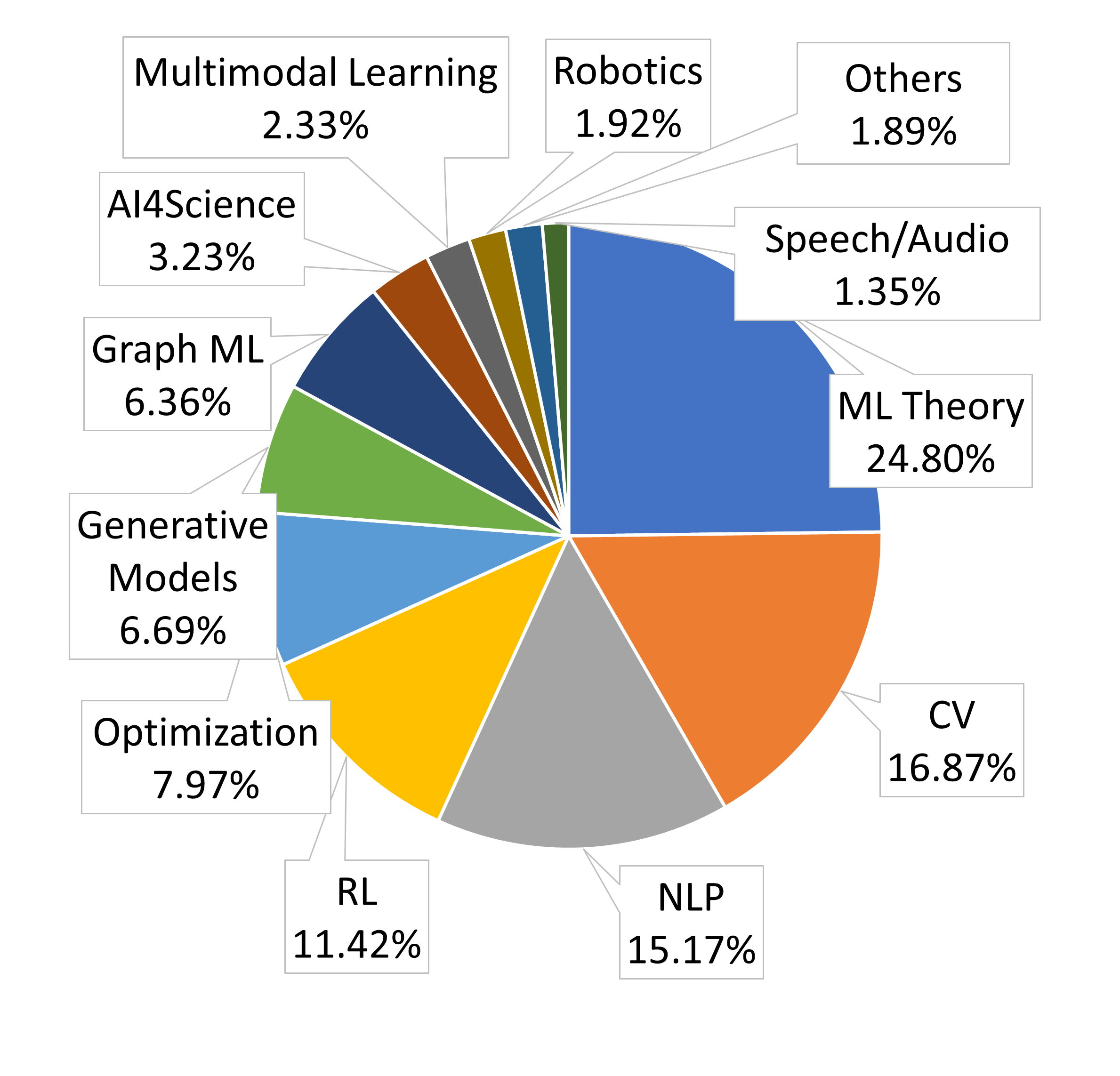
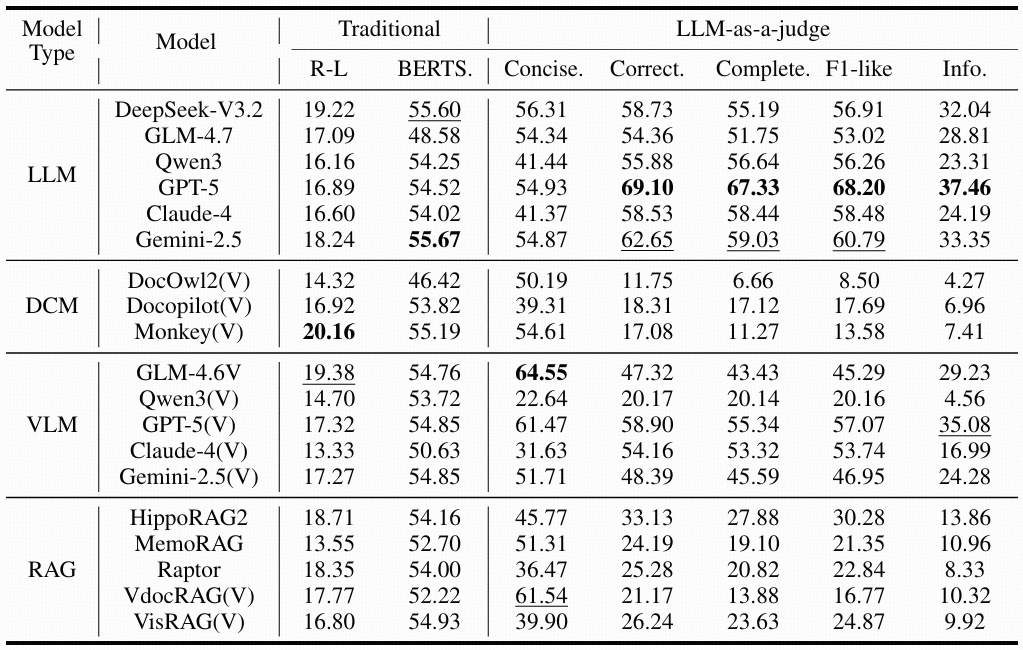
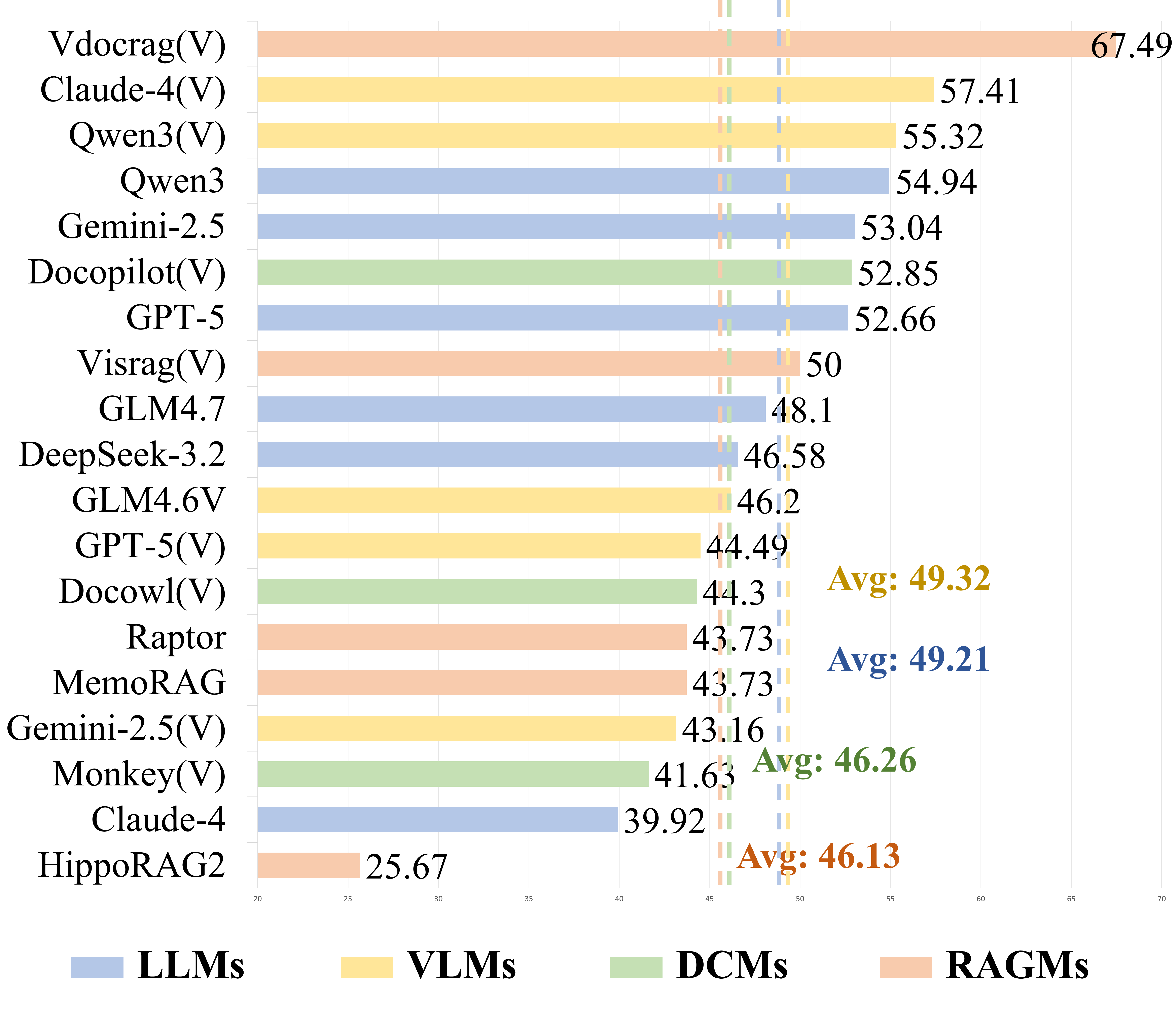
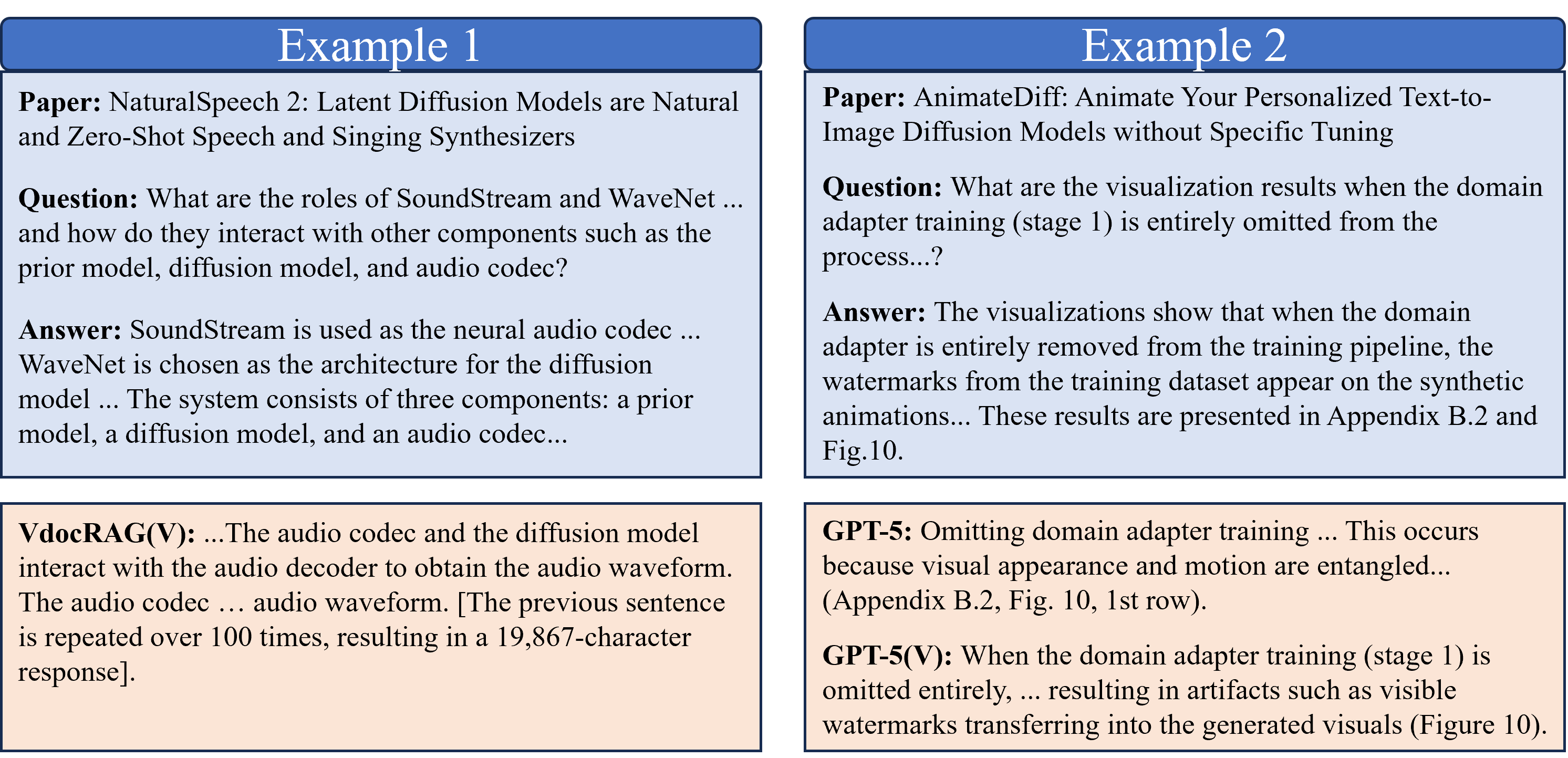
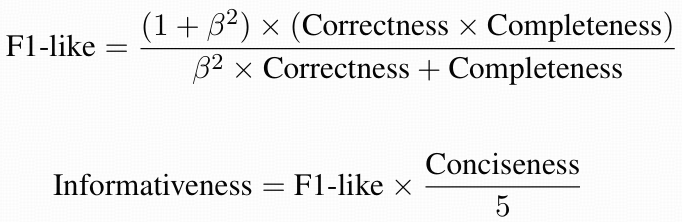Evaluation results on RPC-Bench.
| # | Model | Input Config |
Date | Concise. (%) | Correct. (%) | Complete. (%) | F1-like (%) | Info. (%) |
|---|---|---|---|---|---|---|---|---|
| GPT-5
OpenAI |
TEXT | 2025-8-7 | 54.93 | 69.10 | 67.33 | 68.20 | 37.46 | |
| GPT-5.2
OpenAI |
TEXT | 2025-12-11 | 53.81 | 66.84 | 64.03 | 65.40 | 35.19 | |
| GPT-5
OpenAI |
VISUAL | 2025-8-7 | 61.47 | 58.90 | 55.34 | 57.07 | 35.08 | |
| Gemini-2.5-Pro
|
TEXT | 2025-3-25 | 54.87 | 62.65 | 59.03 | 60.79 | 33.35 | |
| Gemini-3-Pro
|
TEXT | 2025-11-18 | 52.81 | 62.69 | 60.28 | 61.46 | 32.46 | |
| DeepSeek-V3.2
DeepSeek-AI |
TEXT | 2025-12-1 | 56.31 | 58.73 | 55.19 | 56.91 | 32.04 | |
| GPT-5.2
OpenAI |
VISUAL | 2025-12-11 | 56.43 | 56.75 | 52.82 | 54.72 | 30.88 | |
| DeepSeek-V3.1
DeepSeek-AI |
TEXT | 2025-8-21 | 54.76 | 57.85 | 54.85 | 56.31 | 30.84 | |
| GLM-4.6V
Z.ai |
VISUAL | 2025-12-8 | 64.55 | 47.32 | 43.43 | 45.29 | 29.23 | |
| GLM-4.7
Z.ai |
TEXT | 2025-12-22 | 54.34 | 54.36 | 51.75 | 53.02 | 28.81 | |
| GLM-4.5V
Z.ai |
VISUAL | 2025-8-11 | 59.44 | 48.79 | 43.62 | 46.06 | 27.38 | |
| gemini-3-pro
|
VISUAL | 2025-11-18 | 50.22 | 56.06 | 52.69 | 54.32 | 27.28 | |
| GLM-4.5
Z.ai |
TEXT | 2025-7-28 | 43.41 | 58.95 | 59.54 | 59.24 | 25.72 | |
| gemini-2.5-pro
|
VISUAL | 2025-3-25 | 51.71 | 48.39 | 45.59 | 46.95 | 24.28 | |
| Claude-Sonnet-4
Anthropic |
TEXT | 2025-5-23 | 41.37 | 58.53 | 58.44 | 58.48 | 24.19 | |
| Qwen3
Alibaba |
TEXT | 2025-7-21 | 41.44 | 55.88 | 56.64 | 56.26 | 23.31 | |
| Claude-Sonnet-4.5
Anthropic |
TEXT | 2025-9-30 | 31.02 | 64.31 | 64.97 | 64.64 | 20.05 | |
| Claude-Sonnet-4.5
Anthropic |
VISUAL | 2025-9-30 | 31.95 | 55.35 | 54.45 | 54.89 | 17.54 | |
| Claude-Sonnet-4
Anthropic |
VISUAL | 2025-5-23 | 31.63 | 54.16 | 53.32 | 53.74 | 16.99 | |
| HippoRAG2
The Ohio State University |
TEXT | 2025-6-19 | 45.77 | 33.13 | 27.88 | 30.28 | 13.86 | |
| MemoRAG
Peking University & Hong Kong Polytechnic University |
TEXT | 2025-4-9 | 51.31 | 24.19 | 19.10 | 21.35 | 10.96 | |
| VdocRAG
NTT Corporation & Tohoku University |
VISUAL | 2025-4-14 | 61.54 | 21.17 | 13.88 | 16.77 | 10.32 | |
| VisRAG
Tsinghua University & ModelBest Inc. |
VISUAL | 2025-3-2 | 39.90 | 26.24 | 23.63 | 24.87 | 9.92 | |
| Raptor
Stanford University |
TEXT | 2024-1-31 | 36.47 | 25.28 | 20.82 | 22.84 | 8.33 | |
| Monkey
Huazhong University of Science and Technology |
VISUAL | 2024-8-26 | 54.61 | 17.08 | 11.27 | 13.58 | 7.41 | |
| Docopilot
Shanghai AI Laboratory |
VISUAL | 2025-7-19 | 39.31 | 18.31 | 17.12 | 17.69 | 6.96 | |
| Qwen3
Alibaba |
VISUAL | 2025-7-21 | 22.64 | 20.17 | 20.14 | 20.16 | 4.56 | |
| DocOwl2
Alibaba |
VISUAL | 2024-9-9 | 50.19 | 11.75 | 6.66 | 8.50 | 4.27 |
Green date indicates the newly added/updated models.